Vision Detector
通常、CoreMLのモデルはXcode上でプレビューするか、Xcodeでアプリケーションをビルドして実行する必要があります。
Vision Detectorを使うと、CoreMLモデルを簡単に実行することができます。
自分で作成した機械学習モデルを手軽に検証したり、ダウンロードしてきた機械学習モデルを実行するのに最適です。
iPhone/iPad版とMac版があり、それぞれのプラットホームの特性を活かした操作性を目指しています。
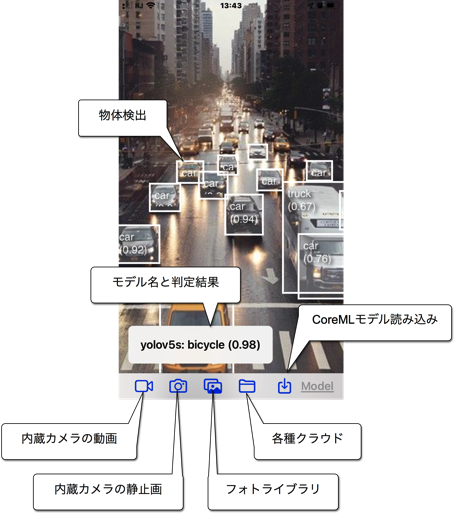
[iPhone/iPadの場合]
用意した機械学習モデルをiPhone/iPadのファイルシステムに入れます。ファイルシステムとは、iPhoneの「ファイル」アプリケーションから見える領域であり、ローカルのデバイス内や各種クラウドサービス(iCloud Drive、One Drive、Google Drive、DropBoxなど)のことです。AirDropなどで転送してもいいでしょう。
アプリを起動し、その機械学習モデルを選択して読み込みます。
画像の入力ソースを、
・iPhone/iPad内蔵カメラからの動画
・内蔵カメラからの静止画
・フォトライブラリの写真
・ファイルシステムの任意の画像データ
から選択します。
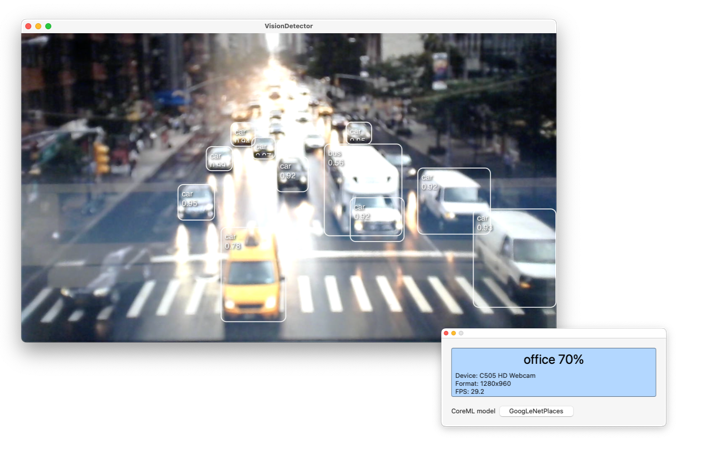
[Macの場合画像]
外部ビデオ入力デバイスがあなたのMacに接続しているときはそちらが優先的に使用されます。
外部デバイスがない場合はMacBookのFaceTimeカメラを使用します。
※このアプリには機械学習モデルは含まれていません。
対応する機械学習モデルは、
・Image classification
・Object detection
・Style transfer
になります。
Non-maximum suppression層を持たないモデルや、MultiArrayの形式でデータを入出力するモデルには対応しません。
iPhoneのローカルの書類フォルダの中にVision Detectorというフォルダがあり、その中にcustomMessageという空のTSVファイルが用意されます。
このファイルにobject detectionの動画処理で表示されるカスタムメッセージを定義することができます。
(YOLOなどが出力するラベル) (tab) (メッセージ)
(YOLOなどが出力するラベル) (tab) (メッセージ)
のように横2列の表データを記述します。
macOSの場合も同様ですが、Sandboxの仕組みの関係上、
~/Library/Containers/jp.thyme.maclab.vision/Data/Documents/customMessage.tsv
という場所にファイルがあります。
![]()